Basic Web Scraping with Python
Cleaning data off a website tutorial
2019/04/03
Suppose we want to create a clean dataset of all Oncology centers in the United States listed on the US Oncology Network website.
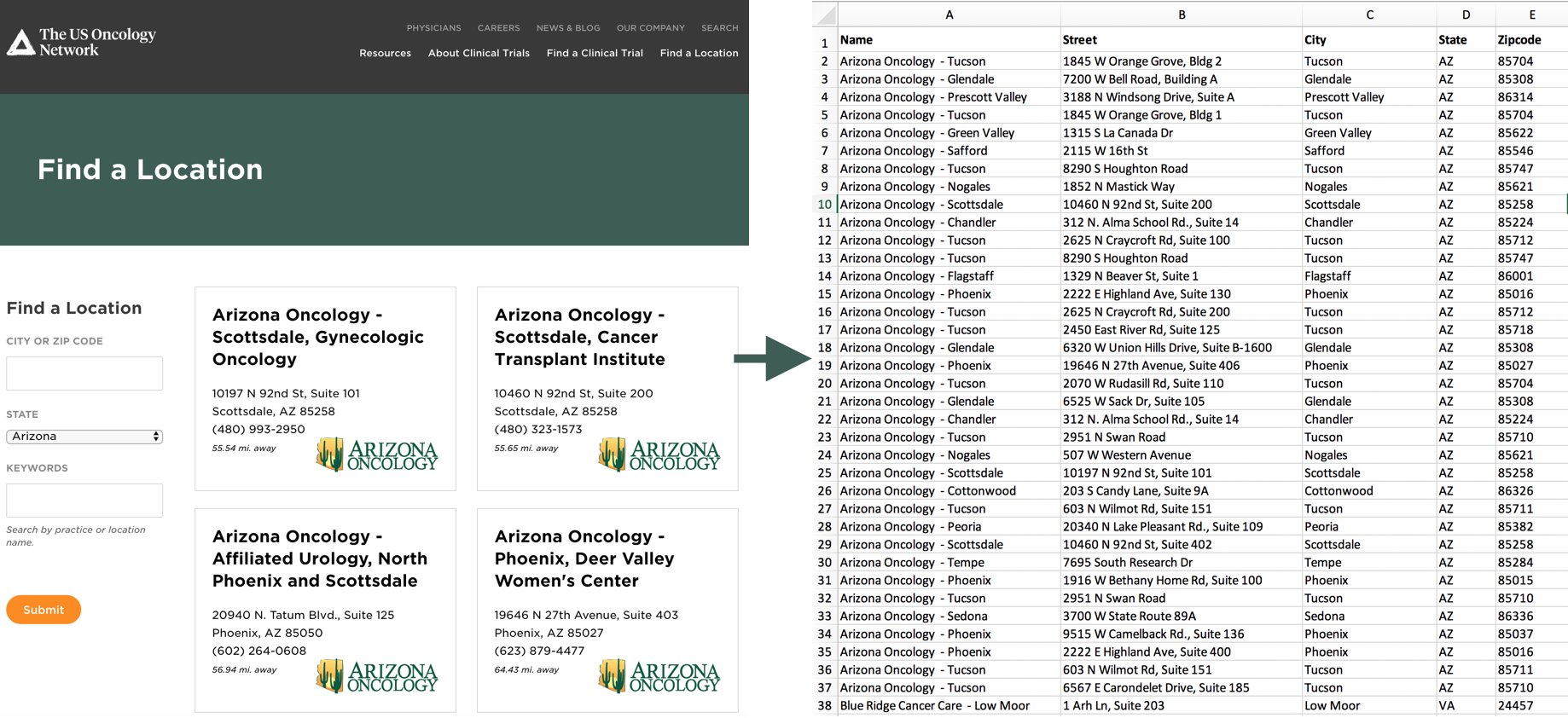 The listing is provided with similar layout cards with 10 cards per page, and 44 pages.
The listing is provided with similar layout cards with 10 cards per page, and 44 pages.
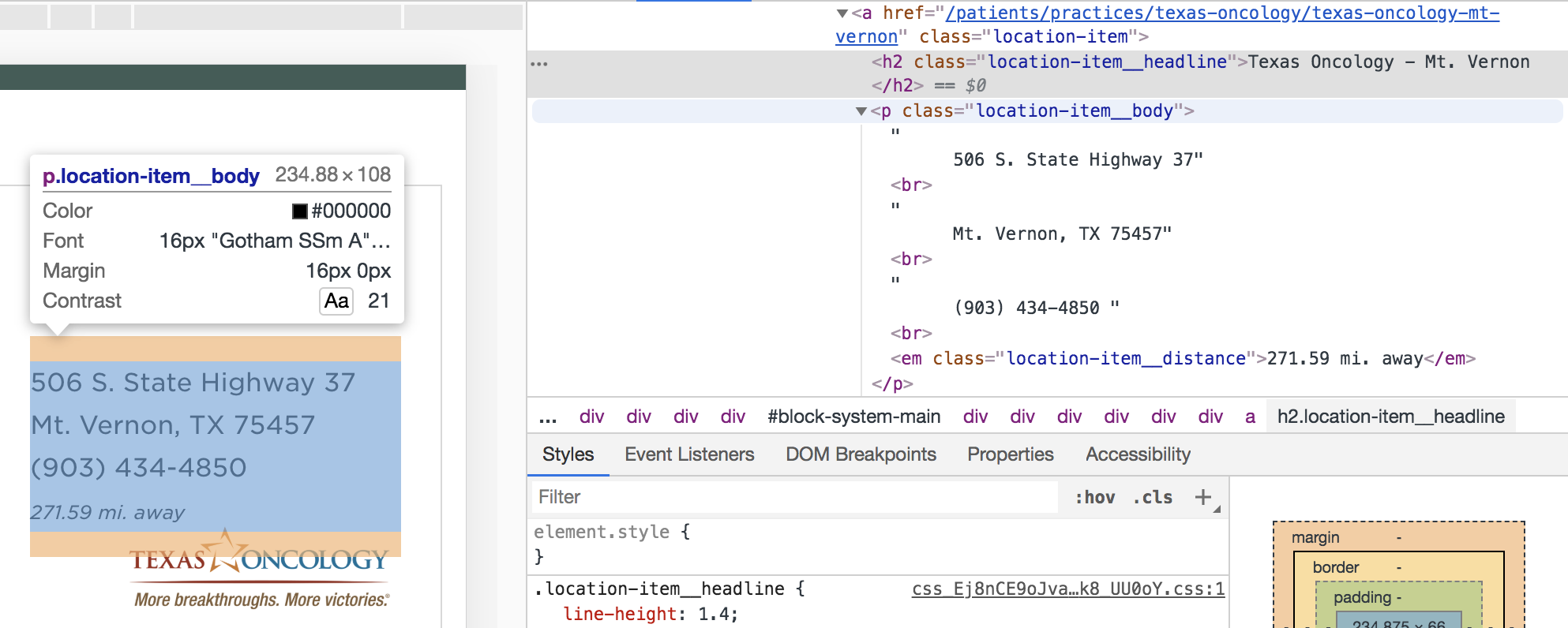
 With Chrome inspector, we find that the title in each card is contained in an h2 with class “location-item_headline”, and each address is in a p with class “location-item_body.”
With Chrome inspector, we find that the title in each card is contained in an h2 with class “location-item_headline”, and each address is in a p with class “location-item_body.”
 We can use the BeautifulSoup package and the soup.find_all function to grab all the h2 with the headline class into a list of all the titles. Repeat find all to make a list with all the addresses by finding all p with body class. These two lists should be of equal length.
We can use the BeautifulSoup package and the soup.find_all function to grab all the h2 with the headline class into a list of all the titles. Repeat find all to make a list with all the addresses by finding all p with body class. These two lists should be of equal length.
from bs4 import BeautifulSoup
import requests
def scrape(url):
src = requests.get(url).text
soup = BeautifulSoup(src, "lxml")
names_raw = soup.find_all("h2", {"class": "location-item__headline"})
addresses_raw = soup.find_all("p", {"class": "location-item__body"})
We can then repeat this process for all the pages. Conveniently, the pagination just changes the number at the end of the URL, so we can loop our scraper over the number of pages. Let’s put a slight delay in before moving to the next page.
import time
for x in range(1, 45):
url = f"https://www.usoncology.com/patients/find-a-location?page={x}"
scrape(url)
time.sleep(0.05)
Now that we have the two raw lists of names and addresses, we need to do a little cleanup. The names list seems to be fine, but the each address has a bunch of blank spaces, new lines, missing data fields, and other noise. Let’s go through the list and split each address into Street, City, State, and Zip. First we clean up the address string, getting rid of the blank spaces in the beginning and splitting by new lines:
for i in range(len(addresses_raw)):
address = addresses_raw[i].text[7:].split("\n")
The first line is the Street:
street = address[0]
The second line before the comma is the City (and eliminating the blank spaces before it):
city = address[1][6:].split(",")[0]
States are two capital letters, located after the comma on the second line. We can search there using a regular expression, and return nothing if two capital letters aren’t found.
import re
state_pattern = re.compile(r"[A-Z]{2}")
try:
state = state_pattern.search(address[1].split(",")[1]).group()
except:
state = "None"
Zipcodes are five digits, also located after the comma on the second line. We can search there using another regular expression, and return nothing if five digits aren’t found.
zip_pattern = re.compile(r"\d{5}")
try:
zipcode = zip_pattern.search(address[1]).group()
except:
zipcode = "None"
Now that we have all our cleaned data for this one hospital, let’s output it to a CSV. We can write in the headers first:
import csv
with open("US_Oncology_List.csv", "w") as file:
writer = csv.writer(file)
writer.writerow(["Name", "Street", "City", "State", "Zipcode"])
And as we’re looping through each address cleaning it up, we can output that to the next row:
writer.writerow([names_raw[i].text, street, city, state, zipcode])
And we’re done! The final code:
from bs4 import BeautifulSoup
import requests
import csv
import time
import re
def scrape(url):
src = requests.get(url).text
soup = BeautifulSoup(src, "lxml")
names_raw = soup.find_all("h2", {"class": "location-item__headline"})
addresses_raw = soup.find_all("p", {"class": "location-item__body"})
for i in range(len(addresses_raw)):
address = addresses_raw[i].text[7:].split("\n")
street = address[0]
city = address[1][6:].split(",")[0]
state_pattern = re.compile(r"[A-Z]{2}")
zip_pattern = re.compile(r"\d{5}")
try:
state = state_pattern.search(address[1].split(",")[1]).group()
except:
state = "None"
try:
zipcode = zip_pattern.search(address[1]).group()
except:
zipcode = "None"
writer.writerow([names_raw[i].text, street, city, state, zipcode])
with open("US_Oncology_List.csv", "w") as file:
writer = csv.writer(file)
writer.writerow(["Name", "Street", "City", "State", "Zipcode"])
for x in range(1, 45):
url = f"https://www.usoncology.com/patients/find-a-location?page={x}"
scrape(url)
time.sleep(0.05)
Happy scraping!